前言
个人浅见,一般分析一个程序可以有动态和静态两条路,动态一般指的就是调试或者别的运行时跟踪程序行为的方式了,除了调试器外就是抓取事件、日志、API调用记录、看内存数据等,比如有 Frida,还有内存搜索如CE。静态则是用各种工具在不实际运行程序的前提下,从程序文件里提取有用的信息。
对于运行时的对抗手段很多,毕竟程序都跑起来了,你来我往打擂台嘛。而且在Windows这个闭源平台上,还可以靠不大可能被动手脚的内核来保护自己,Linux上就可能内核都是被魔改过的。
但是对静态分析就没有什么特别好的办法,又要人造的计算机能正确运行,又要人不能理解,就有点矛盾。
广为人知的对抗静态分析的手段有这些:
- 混淆,把程序逻辑转换成更晦涩但等价的形式。
- 加花,对抗反汇编引擎,利用反汇编工具的算法缺陷、漏洞来迫使分析者必须花费大量时间处理错误的反汇编结果,让诸如控制流视图之类的工具失效。
混淆和加花的主要区别 在我这 定义为 混淆是变换原程序逻辑,花指令不改变原程序逻辑 。
这些对抗手段主要的目的都是 消磨耐心 和 拖延时间 ,抬高人肉分析的成本。但混淆加花这种手段是无法做到只让机器读懂代码而人读不懂这种效果的。这个结论忘了是哪篇论文里提到的了。
本篇只讲如何对抗反汇编,也就是花指令技术。
0x01 花指令原理
1.1 机器码指令格式
码农日常工作接触的是高级语言(这个概念可能有争议,反正相对汇编、机器码这个层级来说都是高级语言就对了),汇编和机器码这种满是历史尘埃的领域是绝无机会接触的。但要理解花指令,首先要理解汇编代码的二进制表示,才会明白为什么反汇编工具的力量是有极限的。
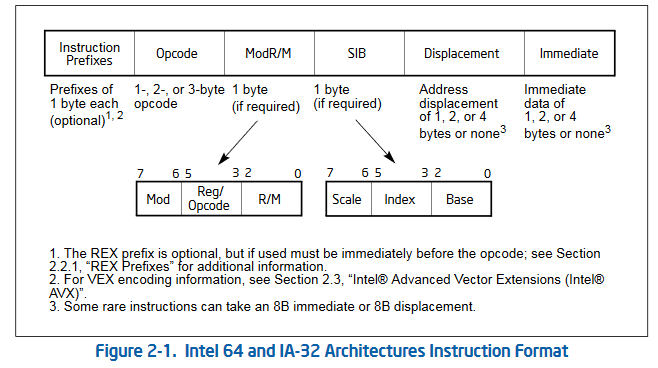
这是 Intel 的 64-ia-32-architectures-software-developer-instruction-set-reference-manual 里的一张图,说明了汇编指令如何以二进制形式保存。可以简单看成3部分,1字节的可选前缀,1-3字节的opcode部分,剩余描述操作数的部分。
几个要素:
- 指令长度不固定,最短 1 字节,最长可能有 14 (图中全部相加,实际会不会有我就不知道了)。
- 一条汇编代码里的指令可能对应很多不同的 opcode ,简单到
add这样的指令也会有很多种不同形式。
熟悉机器码格式在自己构造花指令的时候大概会有用,但实话说 Intel 这手册看得我头痛。所以还是直接快进到花指令原理。
1.2 花指令原理
花指令的英文是 junk code ,也就是垃圾代码。实际上花指令的确是一些不影响程序逻辑的 垃圾 机器码,它存在的唯一意义就是干扰反汇编引擎和人肉分析。
花指令有两种类型:
- 不可执行的花指令
- 可执行的花指令
听起来像是废话但实际上构造这两种花指令的难度是完全不一样的。
对于不可执行的花指令,本质上我们做的事情是在跳转指令之后插入一个多字节指令的字节,欺骗反汇编器将这个字节之后的几个字节当成一个多字节指令解释,进而造成后续指令反汇编出错。
而可执行的花指令,本质是将指令的组成部分重新解释执行。像是一个2字节的跳转指令,第二个字节是操作数,但操作数可以是 0xff,也就是带符号的 -1,使 EIP 落在 0xff 这个字节上,将0xff作为指令继续执行。这个过程中0xff既可以被当成数字0xff解释,也被当成了指令来解释。
1.3 反汇编算法
目前常见反汇编算法就两类,一类是线性反汇编,对输入的数据逐字节翻译成汇编代码。这种反汇编算法多数时候工作地很好,但属于老实人,认为指令总是一个接一个出现,一个简单地在jmp后插入0xe8就能骗到。
另一类是基于代码流分析的算法,这类算法的特点是不会无脑地继续反汇编跳转指令之后的代码,而是去优先反汇编 可达 的代码。像是我们在 C 里面写 if (1) {} else { /* junk code */ },对于足够聪明的编译器,else 分支就是明确无误的垃圾。对于这种反汇编算法,可以通过可执行的花指令来欺骗,或构造反汇编器无法判断真假的恒真/恒假分支,再插入不可执行的花指令来达到欺骗效果。
0x02 花指令案例
2.1 E8 和线性反汇编算法
E8 是 call 指令的 opcode。opcode operation code 也叫指令机器码 Instruction Machine Code,就是汇编指令翻译后的二进制形式。贴一个 wiki 百科的 x86 指令列表 以供参考。还有 x86 instruction set reference 。还有 How does the CPU distinguish 'CALL rel16' (E8 cw) and 'CALL rel32' (E8 cd)?
我们的程序运行在用户模式(32位)模式下,E8 指令后紧跟着的是4字节的相对偏移,一条完整的 E8 指令会使用 5 个字节的空间。
下面是一个 E8 花指令的案例,需要 MinGW 编译,对 x32dbg 有效。
#define ANTI_LINEAR_DISASSEMBLE_ALGORITHM_1 asm("jmp next\n.byte 0xe8;\nnext:\n")
int start(void) {
ANTI_LINEAR_DISASSEMBLE_ALGORITHM_1;
return 0;
}
编译命令
gcc demo.c '-Wl,--entry=_start' -nodefaultlibs -nostartfiles -o demo
调试器内的效果
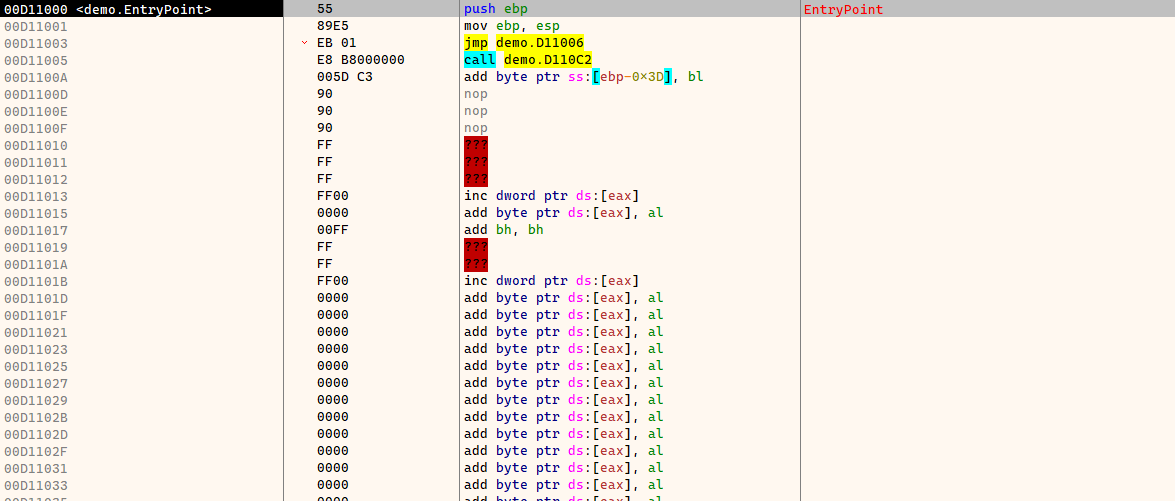
可以看到在 jmp 指令后,反汇编出了一条 call 指令。但实际上我们写的代码里是没有任何函数调用的。而在这个 E8 后面的 B8 00 00 00 00 5D C3 才是真正会执行的代码:
mov eax, 0 ; B8 00 00 00 00
pop ebp ; 5D
retn ; C3
参考intel 80x86 assembly language opcodes。
如果仔细看 jmp 后的偏移 01 的话也能猜到下一个 E8 是不会被执行的。
像是这种简单的花指令在 IDA 里没用,IDA 的反汇编算法会根据控制流分析来判断哪些内容不会被执行,进而产生下面的结果。
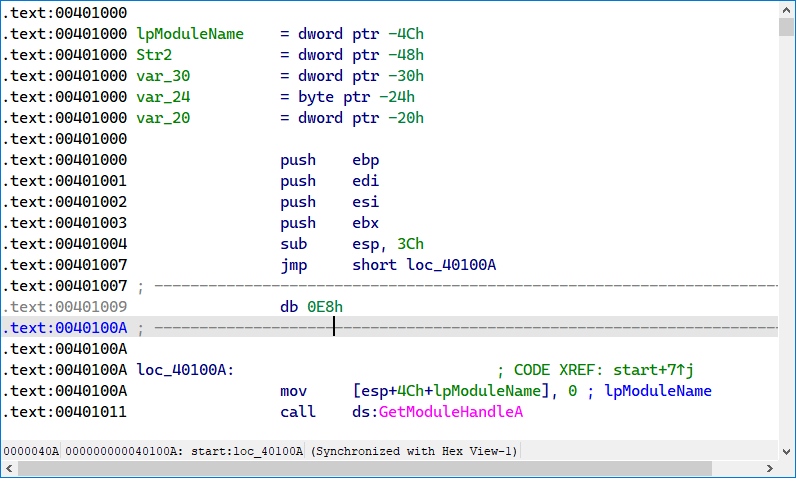
2.2 IDA 和代码流反汇编算法
关于IDA的反汇编算法描述是来自《恶意代码分析实战》。
前面讨论的简单对抗反汇编技术是巧妙地在条件跳转指令之后放一个字节,这种技术的思路是,从这个字节开始反汇编,阻止其后真正的指令被反汇编,因为插入的字节是一个多字节指令的机器码。我们称这样的字节是流氓字节,因为它不属于程序的一部分,只是用在代码段迷惑反汇编器。
IDA的反汇编算法是针对代码流的反汇编,基本思路是记录反汇编过程中的跳转地址作为下一次反汇编的起点,当控制流转移(jmp之类的跳转指令)时,并不是从跳转指令之后继续反汇编,而是从之前记录的跳转地址里选一个,开始新的反汇编工作。如上面的 jmp + e8 就无法对抗这种反汇编算法。
目前实践中也发现,IDA 已经可以识别出一些例如 jz+jnz 制造的无条件跳转,通过控制流指令制造恒真或恒假条件来跳转大概会往更加复杂、高开销的方向走:比如利用系统API、环境中的已知常量作为条件去欺骗IDA,让 IDA 无法轻易认定某条分支是无效分支,进而干扰反汇编结果。
那么除了插入多字节指令还有什么办法对抗代码流分析算法呢?
...但是,如果流氓字节不能被忽略怎么办?如果它是合法指令的一部分,且在运行时能够被正确执行怎么办?这里,我们碰到一个棘手的问题,所有给定字节都是多字节指令的一部分,而且它们都能够被执行。目前业内没有一个反汇编器能够将单个字节表示为两条指令的组成部分,然而处理器没有这种限制。
下面是一个案例。
.byte 0xeb,0xff,0xc0,0x48
0xeb jmp 指令的 opcode,是一个 2 字节指令。0xff 被解释为 -1。
0xff 是 INC 的机器码,0xc0是操作数,表示 eax,也就是 inc eax。可以在这个在线反汇编网站上验证。
0x48 则是 dec eax 的汇编指令,因此这4个字节执行后最终不会影响 eax 的值。
在这里,0xff 同时被解释为 jmp 的操作数和 inc 指令,并且能正常执行,但反汇编器则会被迷惑。

上图是IDA中反汇编的结果。
2.3 构造能欺骗IDA的花指令
构造能欺骗IDA的花指令简单的办法就是构造无法被静态分析的恒真/恒假条件。举例来说,LoadLibraryA 加载失败会返回 NULL,就可以被用来构造花指令。
LoadLibraryA("not-exists.dll");
asm("test %eax,%eax;\njz next;\n.byte 0xe8;\nnext:\n");
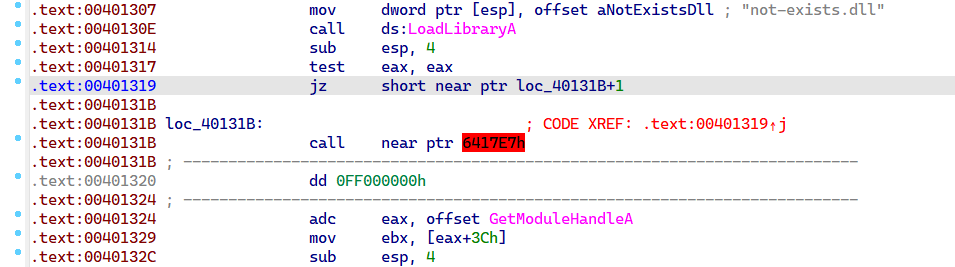
可以看到,IDA不能静态分析出LoadLibraryA 的返回值是 NULL,顺着 jz 的 False 分支反汇编时遇到了 0xe8,于是后续的反汇编结果就完全乱了套。
2.4 破坏栈帧分析
还有一种花指令是通过对 call 和 ret 利用来实现破坏栈帧分析。大家都知道 call 和 ret 就是 push+jmp和pop+jmp,如果我们手动在函数里再构造一个假函数,跳转之后修改栈上的返回地址,返回到我们希望继续执行的位置,虽然本质上是个 GOTO 的操作,但 IDA 就会懵圈了。
一个简单的例子如下,call跳转到下一行,修改返回地址到 continue 后又ret,结果就是在 continue 这个标签处继续执行。
asm(
"call next;\n"
"next:\n"
"movl $continue,(%esp);\n"
"ret;\n"
"continue:\n"
);
产生的代码在IDA里分析会出现这样的 sp-analysis failed。
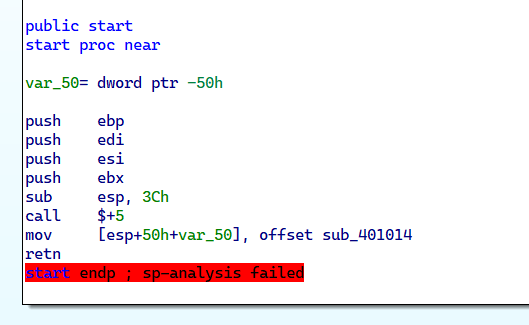
这个思路可以反复嵌套,增加跳转的次数和深度,甚至把正常逻辑隐藏在这种反复跳转中,但从高级语言层面手工加这种花很困难。
再给一个复杂一些的例子,同样是利用了 call 和 ret 来实现花式跳转。
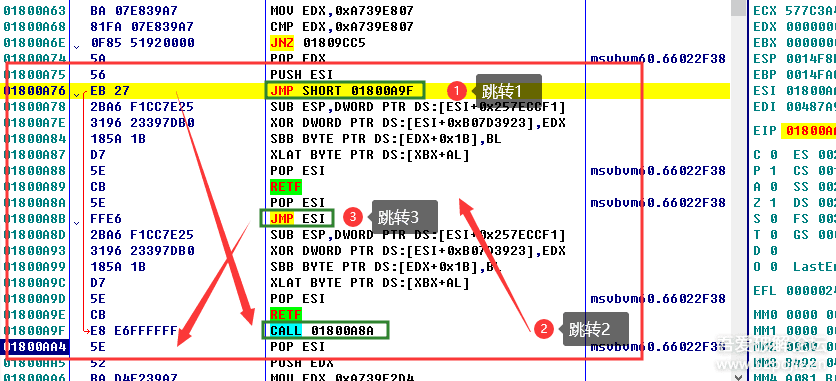
来自52论坛的:一些简单的花指令的解析(含Intel指令集) - 『病毒分析区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn。
顺便一提,链接里那个 pop ss 也很有意思,GrandCrab 的案例也是结合了多种控制流指令来完成跳转,阻碍IDA分析。
总结
首先,不只是E8,不要局限在这里。所有的多字节指令都可以用来构造花指令。花指令也不只是利用多字节指令干扰反汇编,也能精心伪造控制流对抗分析工具的其他高级分析功能,迫使分析者不能无脑F5读伪代码,消磨分析者的时间、精力、耐心。
花指令有很多模式,但一个显著特征是 跳转,必须通过跳转指令来实现越过不可执行的花指令,或通过跳转来实现重新解释已经被解释过的指令的一部分,以及通过连续跳转来隐藏真实跳转地址。所以看到莫名其妙地开始跳起来就要警惕了,这会儿很可能正在分析无效的垃圾代码。
编写花指令的时候应该注意到,花指令对抗的目标不是分析工具,而是分析者。简单地写一个jz和E8也许实现了让分析工具出错的目的,但分析者一眼就能看出这是无效代码,基本无法起到对抗作用。
参考资料:
- 恶意代码分析实战 (豆瓣) (douban.com)
- 一个利用call+ret修改返回地址的花指令分析 - OneTrainee - 博客园 (cnblogs.com)
- 一些简单的花指令的解析(含Intel指令集) - 『病毒分析区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
- Combined Volume Set of Intel® 64 and IA-32 Architectures Software Developer’s Manuals
- [原创]汇编指令之OpCode快速入门-软件逆向-看雪论坛-安全社区|安全招聘|bbs.pediy.com
- x86 and amd64 instruction reference (felixcloutier.com)
- Intel 80x86 Assembly Language OpCodes (mathemainzel.info)
- online x86 disassembler
- 花指令模糊变换策略研究与实现 - 豆丁网 (docin.com)
特别推荐最后这篇论文,我没找到在哪儿能下,就放原链接了。直接百度学术搜花指令也能找到很多有意思的文章(尽管形式化描述的部分基本都没看懂)。
自动化的加花方式基本要求在汇编层面去重排代码或者插入代码,直接在二进制文件上加花我寻思了一下是蛮难的,主要是正常程序代码段里随便插东西的话,重定位和重新算各种文件字段很麻烦。所以吧...大概在编译器层面(LLVM?或者对生成的汇编文件下手)才会比较好施展开。